The future of Earth Observation lies inside Visual Language AI Models
By Emiliano Kargieman, CEO & Founder
The “ChatGPT 3.5 moment” for Earth Observation is coming
Soon, we will no longer have to rely on analysts to manually process satellite images and fuse them with other ancillary data in custom geospatial processing pipelines to extract the insights we need. Instead, we will interact with large Earth Observation AI models with access to high-resolution, real-time imagery of our planet to derive those insights. Multi-modal foundation models combining vision and language create internal representations of the world that allow them to tackle even questions they haven’t been trained on. Over time, they may predict trends before they even happen.
From the day we started Satellogic with the vision to remap the Earth every day in high-resolution, we knew that algorithms that could process imagery as it came from the satellites would be key. After all, if we are generating 150,000,000 km2 of data, at 70 cm native resolution, we are bringing over 300 trillion pixels (over 150 TB of data) down to Earth every single day. If it only took 5 seconds to look at each square kilometer of imagery, a single person would need 80 years to look at the entire planet. It would take 10,000 people to complete the task in 24 hours, before a new batch of data hits their desk: good luck making any sense of that! So how do you derive insights at a global scale? For that you need algorithms.
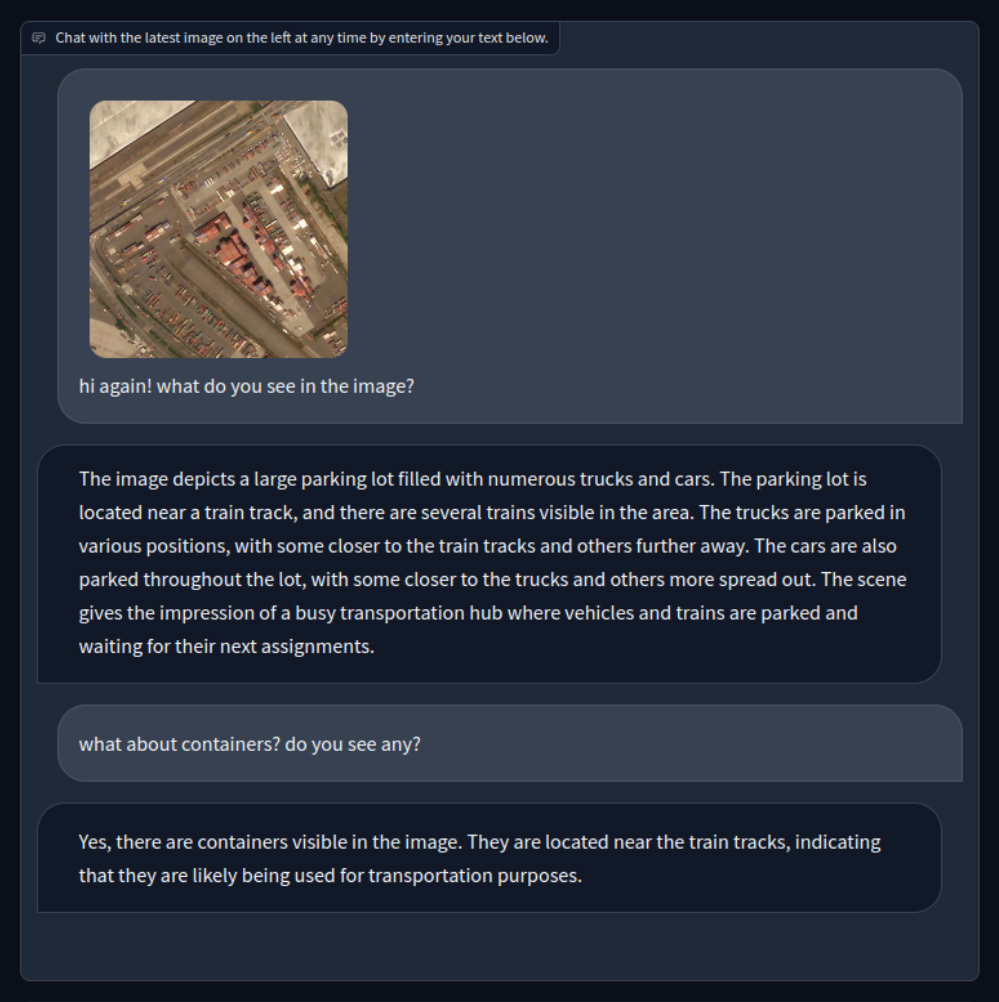
Off-the-shelf Llava-1.5 discussing the contents of a Satellite Image
After the renaissance of AI with deep learning, circa 2012, we finally started to see a path to the tools that we would need: deep neural nets could be trained to perform a number of key tasks over different types of imagery: object detection, semantic and instance segmentation, scene classification, change detection and anomaly detection. Their performance quickly surpassed traditional computational geometry algorithms, and started to achieve and sometimes surpass human capabilities. These algorithms were learning to identify what we wanted to look for in the images, and we could already see that this was the path to an engine that would let us look for things and patterns at a planetary scale. Most importantly for us in the EO world, we didn’t even need to develop these algorithms: we could ride the wave of people looking for cats on the Internet.
Satellogic Mark V satellites capture high-resolution imagery economically, enabling frequent world remaps.
Enter Large Language Models: over the last eighteen months we learnt that by training large-scale transformer models with billions of parameters over vast amounts of data, something special starts to happen: the models start to develop an internal representation of the world as seen through language that is so complete and complex that it no longer feels machine-like. We will all remember the “ChatGPT 3.5 moment” (or “ChatGPT 2”, for those of you on the bleeding edge), when we interacted with these models for the first time, and a simple realization dawned on us: our interaction with the corpus of human knowledge had forever changed.
Visual-Language models trained on vast amounts of Earth Observation data will construct the most accurate representation of Earth we’ve ever had, and change forever the way we understand and interact with our world.
As LLMs learn a representation of the world through language, VLMs (Visual-Language models) learn a representation of the world through a mix of modalities: images or video, and language. Large VLMs trained on vast amounts of pictures and video are already producing images and movies, turning sketches into software, powering robots to interact with the environment, helping you identify the right tools to fix your bike, or helping you complete your geometry homework. VLMs trained on vast amounts of Earth Observation data will construct the most accurate representation of Earth we’ve ever had, and change forever the way we understand and interact with our world.
This will be the true democratization of Earth Observation. The “ChatGPT 3.5 moment” for Earth Observation is coming. We at Satellogic are both uniquely positioned and deeply committed to bringing this new superpower to everyone. Stay tuned.